Major Announcement: A New Challenger in the Multimodal Arena
The competition in artificial intelligence is evolving at an unprecedented pace, with each significant technology release potentially reshaping the industry landscape. Recently, Zhiyu AI, stemming from Tsinghua University’s technology transfer, made a groundbreaking announcement by officially launching and open-sourcing its next-generation visual reasoning model, GLM-4.5V. This move signifies more than a routine model iteration; it represents a carefully orchestrated strategic layout aimed at positioning Zhiyu AI at the forefront of the future AI technology battlefield.
1.1. A Strategic Release
Zhiyu AI’s announcement is clear and powerful. GLM-4.5V is not only being pushed to market but is also being simultaneously open-sourced in two of the world’s leading AI communities: ModelScope and Hugging Face. This initiative sends a clear signal that Zhiyu AI intends to leverage the power of global developers to build an ecosystem around its core technology. This is not merely a sharing of technological achievements but a meticulously designed strategic action aimed at seizing industry discourse power.
1.2. Core Declaration: Performance, Parameters, and Openness
To stand out in the bustling AI market, Zhiyu AI has equipped the release of GLM-4.5V with a striking core declaration:
- Outstanding Performance Certification: The official claim is that GLM-4.5V achieves State-of-the-Art (SOTA) levels of performance across 41 to 42 publicly recognized visual multimodal benchmarks. This quantified performance endorsement aims to swiftly establish its authoritative position in the multimodal domain.
- King of Hundreds of Billions of Parameters: Zhiyu AI boldly asserts that GLM-4.5V is the best-performing model among the global 100B (hundred billion) level open-source visual models. This confident statement directly challenges all competitors in the same parameter range.
- Complete Openness: Unlike some “open-source” models with restrictive clauses, GLM-4.5V and its predecessor GLM-4.1V-Thinking adopt a very permissive MIT license. This means that any individual or enterprise can use, modify, and even commercialize it for free. This thorough openness is key to attracting and uniting the developer community and building ecological barriers.
1.3. Immediate Community Response
The market’s reaction validates the precision of Zhiyu AI’s release. As soon as the news broke, it sparked lively discussions in the largest AI developer communities, such as the r/LocalLLaMA subreddit on Reddit. Developers showed keen interest in the model’s performance and quickly raised practical deployment requests, such as integration requests for GLM-4.5V in the popular local inference framework Ollama’s GitHub repository shortly after the release. This indicates a significant, unmet demand in the market for high-performance, truly open multimodal large models.
Zhiyu AI’s series of actions, from the timing of the release to the choice of open-source agreements, demonstrates its thoughtful strategic intent. It is not merely contributing code to the open-source community but launching a carefully planned initiative aimed at seizing developer minds and defining the standards for the next generation of multimodal technology. By positioning itself as a leader in the open-source domain, Zhiyu AI is laying a solid foundation for its grander strategic goal—dominating the AI Agent track.
Technical Deconstruction: Delving into the Core Architecture of GLM-4.5V
The confidence behind GLM-4.5V’s leading position stems from a series of advanced and efficient technical architecture designs. To understand its strengths, one must delve into its internals to explore how it balances performance, efficiency, and functional diversity.
2.1. Solid Foundation: The Strong Genes from GLM-4.5-Air
First and foremost, GLM-4.5V is not an isolated creation but is built upon Zhiyu AI’s next-generation flagship text base model, GLM-4.5-Air. This lineage is crucial as it means that GLM-4.5V naturally inherits its predecessor’s strong language understanding, logical reasoning, and code generation capabilities. In multimodal tasks, visual information must be encoded and deeply integrated with the language model for reasoning. A robust language base is a prerequisite for achieving advanced visual reasoning. GLM-4.5V stands on the shoulders of such a “giant.”
2.2. Advantages of MoE Architecture: Perfect Balance of Scale and Efficiency
GLM-4.5V employs the cutting-edge Mixture-of-Experts (MoE) architecture in the field of large language models. This can be understood as a system of an “expert committee.” Traditional large models require all parameters to be activated for any task, akin to a polymath solving all problems single-handedly. In contrast, the MoE architecture divides the model into multiple “expert networks,” and when processing a specific input, the system intelligently selects a small subset of the most relevant “experts” to collaborate.
- Specific Parameters: GLM-4.5V has a total parameter count of 106 billion (106B), but during actual inference calculations, only 12 billion (12B) parameters need to be activated.
- Core Advantage: This revolutionary design allows the model to possess knowledge capacity and performance close to a dense 106 billion parameter model while achieving inference speed and hardware resource consumption comparable to a 12 billion parameter model. This greatly optimizes deployment costs and inference efficiency, providing enterprises and developers with an unprecedented high cost-performance solution, addressing the core pain point of “unaffordable” large models.
2.3. The “Thinking” Paradigm: Evolution from Perception to Reasoning
One of the most striking innovations of GLM-4.5V is its continuation and development of the “Thinking” paradigm pioneered by the GLM-4.1V-Thinking model. This is not just a function but a philosophical reflection on the working mode of AI.
- “Thinking Mode” Switch: The model provides a “ThinkingMode” switch. In the off state, the model quickly gives direct answers like traditional models. However, when turned on, the model engages in step-by-step, explicit internal reasoning before generating the final response. These reasoning processes are encapsulated within special
… tags and are not output as final answers, simulating the “thinking” process humans undergo when solving complex problems. - Value of Mixed Reasoning: This design grants users the freedom to choose between “speed” and “depth.” For simple tasks, immediate responses can be pursued; for complex problems, a slight sacrifice in time can yield more reliable and logical answers.
- Technical Support: This advanced reasoning ability is further enhanced by a training technique called “Reinforcement Learning with Curriculum Sampling (RLCS),” which significantly boosts the model’s complex reasoning capabilities through a curriculum training approach that progresses from easy to difficult.
This “Thinking” paradigm is a core capability tailored by Zhiyu AI for the AI Agent era. Agents execute complex, multi-step tasks, such as operating software, browsing the web, and analyzing data, which require not just instantaneous perception but reliable planning and reasoning. By making the reasoning process explicit, developers can better understand the model’s decision logic, enabling debugging, optimization, and ultimately building trust in AI Agents. This marks a shift of AI from a “black box” perception tool to a comprehensible and trustworthy “thinking partner.”
2.4. Full-Spectrum Visual Capabilities: A True Multimodal “Swiss Army Knife”
GLM-4.5V’s capabilities are extensive, far exceeding simple “image captioning,” making it a genuine multimodal workstation:
- Image Reasoning: Capable of deep scene understanding, complex multi-image joint analysis, and spatial relationship recognition.
- Video Understanding: Supports long video shot segmentation, key event identification, and content summarization. It can handle up to 300 images or 1 video input in a single prompt.
- Document and Chart Parsing: Able to extract information from lengthy PDFs like research reports and financial statements and understand complex chart data.
- GUI Agent Tasks: Equipped with capabilities for screen text reading, icon recognition, and desktop operation assistance, making it an ideal foundational model for building robotic process automation (RPA) and graphical interface AI Agents.
- Visual Grounding: The model can accurately locate objects within images and output their bounding box coordinates using special <|begin_of_box|> and <|end_of_box|> tags.
In summary, GLM-4.5V builds a solid technological barrier through its powerful language base, efficient MoE architecture, revolutionary “Thinking” paradigm, and comprehensive multimodal capabilities. It not only pursues excellence in performance but also demonstrates foresight in architectural design, precisely targeting the next wave of AI development—the Agent era.
Competitive Landscape: Positioning GLM-4.5V in a Crowded Field
In the current heated AI arms race, the release of any new model must undergo the most rigorous scrutiny from the market. This chapter will objectively assess GLM-4.5V’s true position in the fierce competition by combining official claims, community feedback, and horizontal comparisons.
3.1. Interpretation of the Benchmark Wars
Zhiyu AI claims that GLM-4.5V achieves SOTA performance across 42 public benchmark tests, which undoubtedly sends a strong market signal. These benchmarks (such as MathVista, MME, DocVQA, etc.) comprehensively cover various capabilities from mathematical reasoning to document understanding, and high scores represent the model’s hard power in these structured tasks. However, it should also be recognized that benchmark scores do not fully equate to real-world user experiences. The model may have been optimized for specific benchmarks while performing differently on some “non-standard” and more casual everyday tasks.
3.2. Showdown Among Open Source Giants
The release of GLM-4.5V places it directly in competition with the world’s top open-source multimodal models. Community discussions and comparisons mainly focus on several key competitors:
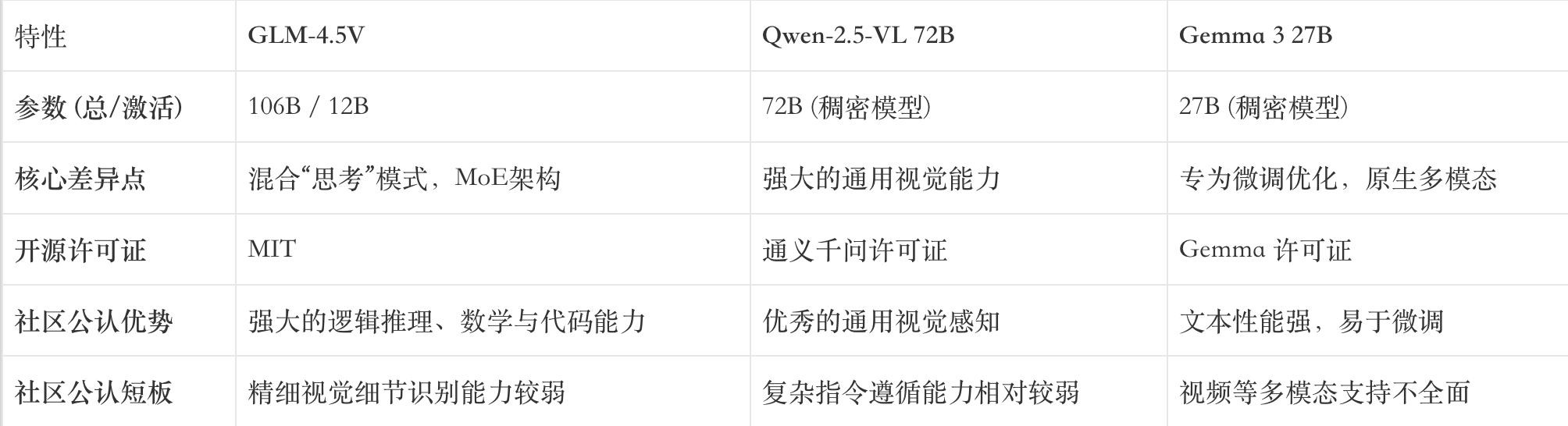
- Alibaba’s Qwen-2.5-VL: As another powerful open-source multimodal model, the Qwen series is well-regarded for its visual capabilities. Community feedback indicates that Qwen-2.5-VL may perform comparably to GLM-4.5V in pure visual perception tasks, and in some aspects, it may even outperform it. However, some users point out that it may not follow complex instructions as well as some top pure text models. GLM-4.5V’s advantage lies in its construction on the strong GLM-4.5-Air text base, theoretically providing stronger instruction-following and reasoning capabilities while filling this market gap.
- Google’s Gemma3: The Gemma series is known for its excellent text performance and fine-tuning friendliness. Developers in the community often use it for highly customized scenarios. However, Gemma3 has shortcomings in native video understanding. GLM-4.5V offers a more comprehensive multimodal capability, including video understanding, aiming to become a more universal “integrated” solution.
- Other Heavyweights: Additionally, models like Baidu’s ErnieVL and Shanghai AI Lab’s Intern-S1 represent high-level open-source multimodal technology, collectively forming the fierce competitive environment that GLM-4.5V faces.
3.3. Community Verdict: A Nuanced Reality
A deep analysis of real feedback from the developer community paints a more nuanced performance picture than official rankings:
- Recognized Strengths: The community generally praises GLM-4.5V (and its parent GLM-4.5-Air) for its reasoning and mathematical capabilities. Users have found that even a highly quantized (3-bit) version of the model can provide precise answers to complex scientific questions, outperforming many other local models. Its performance in agent and code-related tasks is also highly regarded, with some users believing that GLM-4.5-Air outperforms models with far more parameters.
- Exposed Weaknesses: However, a recurring critical point points to the model’s shortcomings in perceiving fine visual details. A Reddit user sharply noted, “It can’t read clocks or recognize the numbers on a D20 die; it performs extremely poorly in focusing on any details in images.” This feedback reveals the model’s “Achilles’ heel”: despite its strong macro reasoning abilities, it has notable shortcomings in the precise identification of micro-visual elements.
This performance differentiation may stem from the inherent emphasis of the model architecture. GLM-4.5V’s reasoning-first design, inherited from GLM-4.1V-Thinking, shines in benchmark tests requiring logical chains. However, tasks like recognizing clocks or die numbers rely more on the visual encoder (Vision Transformer, ViT) for the representation of raw image information.
Community criticisms suggest a certain imbalance between its powerful language reasoning backend and a possibly “standard” visual encoding frontend. As one user pointed out, the issue might lie in “using the same terrible ViT model to encode images.” To achieve comprehensive victory in the next phase of competition, Zhiyu AI may need to enhance not only its reasoning core in future versions but also significantly improve its frontend visual perception capabilities, such as adopting the community-desired “native multimodal” pre-training methods.
3.4. Open Source Visual Language Model (VLM) Competitiveness Matrix
To visually present GLM-4.5V’s market positioning, the following table summarizes its key characteristics compared to major open-source competitors.
Developer Handbook: Practical Guide to Deploying and Using GLM-4.5V
The success of a model depends not only on its performance but also on whether the developer community can easily access, deploy, and use it. Zhiyu AI has demonstrated a profound understanding of this, providing full-path support for users of varying levels from “zero-threshold” experiences to “professional-level” deployments.
4.1. Three Experience Paths: From Zero to Demonstration in Minutes
Zhiyu AI has carefully designed three different access methods, significantly lowering the user entry barrier:
- Path A: Online Demonstration (Most Convenient): For users who wish to quickly experience the model’s capabilities, they can directly access the official chat.z.ai website or the online demo on Hugging Face Spaces. No installation or configuration is required; users can upload images, PDFs, or videos through their browsers and immediately interact with the model to intuitively feel its multimodal processing capabilities.
- Path B: Desktop Assistant (User-Friendly): Zhiyu AI provides a desktop application called vlm-helper.app for macOS users. This application integrates practical features like screenshotting, screen recording, and floating windows, saving chat records in a local database for a seamless native experience. It is important to note that on the first run on macOS, users need to execute the command
xattr -rd com.apple.quarantine /Applications/vlm-helper.appin the terminal to lift the system’s security isolation restrictions. - Path C: Self-Hosted Deployment (Complete Control): For advanced developers and enterprises needing deep integration and customization, model weights can be directly downloaded from Hugging Face or the ModelScope community for local deployment.
4.2. Deployment Tech Stack: Hardware and Software Requirements
Self-hosting the powerful GLM-4.5V requires corresponding hardware and software support:
- Hardware Requirements: Although GLM-4.5V is based on a relatively lightweight Air version, its hundred billion parameter scale still imposes high hardware demands. For reference, its larger sibling model GLM-4.5 (355B) requires over 1TB of server memory and 8 NVIDIA H100 GPUs for optimal performance. Deploying GLM-4.5V also requires professional-grade GPUs with large memory.
- Inference Framework: Zhiyu AI officially supports mainstream efficient inference frameworks like vLLM and SGLang, providing detailed startup command examples, including setting tensor parallelism (–tensor-parallel-size) and allowing local file access (–allowed-local-media-path) among key parameters.
- Community Ecosystem Support: Notably, the open-source community is actively integrating the GLM-4.5 series models into lighter inference engines like llama.cpp. This progress is crucial as it will make running the model on consumer-grade hardware possible, greatly expanding the model’s application range and developer base.
4.3. Efficiency Practices: Advantages of the FP8 Quantized Version
To further lower deployment barriers, Zhiyu AI released the GLM-4.5V-FP8 version alongside the model.
- FP8 Quantization Explained: FP8 is a low-precision floating-point format. By quantizing model weights from standard FP16 (16-bit floating-point) to FP8 (8-bit floating-point), the model’s memory usage can be reduced by about half (FP16 version around 20GB, FP8 version around 10GB) with minimal performance loss on compatible hardware (such as NVIDIA H100 series GPUs), significantly improving inference speed.
- Practical Significance: Providing an official FP8 version indicates that Zhiyu AI is not only pursuing theoretical peak performance but also focusing on the economic feasibility and practicality of the model in real-world deployments. This initiative enables more resource-constrained developers and small to medium enterprises to afford and leverage this powerful model.
4.4. Customization and Fine-Tuning
For users with specific domain needs, GLM-4.5V supports further fine-tuning. Popular one-stop fine-tuning platforms like LLaMA-Factory have already added support for this model, allowing developers to utilize their data for customized training to adapt to specific application scenarios.
Zhiyu AI’s comprehensive release and support strategy can be considered a textbook-level developer ecosystem operation. From instant online demos that satisfy curiosity to desktop assistants for deep integration workflows, and deployment scripts and quantized versions for professional users, it successfully covers the entire user spectrum from individual enthusiasts to large enterprises. This strategy of “minimizing friction” aims to maximize the model’s adoption and embedding into global developers’ toolchains and workflows before competitors can react, thereby building an insurmountable ecological network effect.
Strategic Analysis: Decoding Zhiyu AI’s Open Source Strategy
Zhiyu AI’s open-sourcing of GLM-4.5V is far from a simple technical showcase or community contribution; it conceals a clear, coherent, and ambitious commercial and ecological strategy. This chapter will integrate all previous analyses to deeply decode Zhiyu AI’s grand blueprint.
5.1. Agent-Centric: Building the Core Engine for Future AI
Zhiyu AI’s strategic goal is succinctly captured by its insiders and industry analysts: “Seize the dominance in the Agent track.” In the current stage of AI development, mere Q&A or content generation is no longer cutting-edge; AI Agents capable of autonomously understanding, planning, and executing complex tasks are widely seen as the next technological singularity and commercial blue ocean.
- Born for Agents: The GLM-4.5 series, including the visually capable GLM-4.5V, is designed as a foundational model for agents. They unify reasoning, coding, tool usage, and multimodal understanding—core capabilities required for agents—aiming to become the “central processor” driving the next generation of AI applications.
- Open Source as Leverage: Open sourcing is the core leverage for achieving this strategic goal. By freely providing a powerful and commercially friendly “engine,” Zhiyu AI incentivizes global developers to build various Agent applications on its technological foundation. When a multitude of applications, tools, tutorials, and talents coalesce around the GLM architecture, a strong “open-source ecological barrier” or “moat” is naturally established. This makes it difficult for newcomers, even with comparable performance models, to shake the network effects and developer habits already formed around GLM.
5.2. Business Flywheel: A Closed Loop from Open Source Community to API Revenue
Zhiyu AI’s business model clearly illustrates a “flywheel effect” from open source to profitability:
- Release & Attract: Free provision of a top-tier open-source model (GLM-4.5V) under a permissive MIT license to attract the broadest range of developer attention and usage.
- Adopt & Embed: By offering online demos, desktop applications, and convenient deployment tools, it promotes rapid adoption and deep integration of the model within the developer community, embedding it as the tool of choice.
- Convert & Monetize: As developers or enterprises transition from experimental projects to commercial products, their demand for the model’s stability, reliability, scalability, and technical support will surge. At this point, Zhiyu AI can guide them to its commercial large model open platform, Bigmodel.ai, which offers optimized, enterprise-level API services on a paid basis to meet professional user needs.
The pricing page for Zhiyu’s large model open platform clearly lists GLM-4.5V as the flagship visual model and provides detailed API call pricing, showcasing a direct conversion path from open-source projects to commercial products. Once this flywheel starts turning, the prosperity of the open-source community will continuously bring potential customers to the commercial platform, while the revenue from the commercial platform can further fund the development of higher-level models, which in turn can be released as open-source, reinforcing the community’s leading position and forming a positive cycle.
5.3. Community Voice: A Crowdsourced R&D Roadmap
Zhiyu AI’s open-source strategy has also brought it another valuable intangible asset: direct market feedback from frontline developers worldwide. A discussion thread on Hugging Face titled “Wishlist for GLM-5” serves as a tailored, market-driven R&D roadmap for Zhiyu AI.
The core demands of the community clearly point towards future development directions:
- Native Multimodal: Developers hope future models can process text, images, videos, and more simultaneously from the pre-training stage, achieving deeper cross-modal understanding rather than merely appending a visual module to a text model.
- Stronger Context Handling: The community expects models to support million (1M) level ultra-long context windows and improve information extraction accuracy in long context environments.
- Richer Model Sizes: In addition to high-performance large models, the community strongly calls for the release of smaller models that can run on consumer-grade hardware to expand the user base and application scenarios.
- Deep Binding with Core Ecosystem: Developers hope Zhiyu AI will proactively collaborate with popular inference engine communities like llama.cpp to ensure that new model releases receive the broadest support from Day 1.
This “wishlist” is a more valuable asset than any market research report. It allows Zhiyu AI to accurately grasp developers’ pain points and expectations, ensuring that its future R&D investments align perfectly with market demands, thereby maintaining a leading edge in fierce competition.
In conclusion, Zhiyu AI’s open-source strategy is a combination of tactics that cleverly integrates technological leadership, community ecosystem building, and commercialization. This is a classic platform strategy, where core technology is “commodified” to seize the market, and then value is extracted at the service level. This strategy enables it to harness the collective intelligence of the community to compete with closed-source models while providing a clear commercial model for sustainable innovation, thus gaining an advantage in the competition with other open-source projects.
Conclusion: Key Insights and Future Outlook
The open-sourcing of GLM-4.5V marks a new phase in the global AI race. Its impact extends far beyond the technical realm of a new model, providing profound insights into industry development directions, competitive modes, and ecological construction.
6.1. Summary of Event Significance: A Dual Victory in Technology and Strategy
The release of GLM-4.5V is more a strategic masterpiece than a mere showcase of technological achievements. It successfully consolidates multiple key advantages:
- Outstanding Performance: At its core, it sets a new benchmark in multiple structured task benchmarks with its powerful reasoning.
- Efficient Architecture: The innovative MoE design and FP8 quantization support effectively address the cost and efficiency challenges of deploying large models.
- Ultimate Openness: The thorough MIT commercial license and comprehensive developer tool support lay the foundation for rapid expansion of its ecosystem.
This model, which integrates top-tier performance, economic efficiency, and developer-friendliness, has garnered significant market momentum right from its release.
6.2. A New Benchmark for Open Source
This release undoubtedly raises the bar for top open-source visual language models. Future open-source projects may no longer be able to form strong competitiveness merely by releasing model weights. The market will expect a more complete “solution package”: a powerful foundational model, an advanced paradigm centered on reasoning, a series of convenient usage tools like desktop assistants, and a quantized version that considers actual deployment costs. GLM-4.5V sets a new, higher standard for the industry, forcing all competitors to reassess their open-source strategies.
6.3. Future Outlook: The Battle for Agents Has Begun
The emergence of GLM-4.5V is a clear signal that the focus of the AI industry is shifting from “model performance competition” to “agent capability competition.” Future competition will no longer be solely about comparing model scores on static leaderboards but about who can build more powerful, reliable, and interactive multimodal AI Agents with the digital and physical world.
Zhiyu AI has fired the crucial first shot in this new war. It wields open-source as a weapon and targets Agents, constructing a highly promising technological ecosystem. Its future success will depend on its ability to continuously nurture and respond to the open-source community that sustains it while effectively converting community prosperity into sustainable commercial momentum. The entire industry will closely watch how other giants—whether in the open-source or closed-source camp—will respond to the bold and profound challenge posed by Zhiyu AI. The war for the Agent era has officially begun.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.